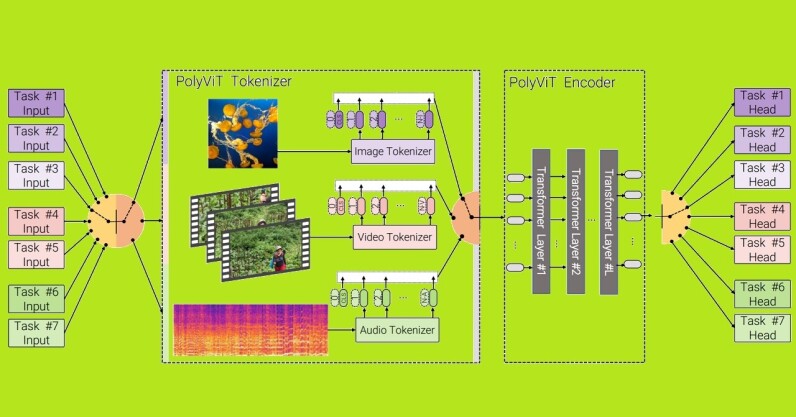
A team of scientists from Google Research, the Alan Turing Institute, and Cambridge University recently unveiled a new state of the art (SOTA) multimodal transformer for AI. In other words, they’re teaching AI how to ‘hear’ and ‘see’ at the same time. Up front: You’ve probably heard about transformer AI systems such as GPT-3. At their core, they process and categorize data from a specific kind of media stream. Under the current SOTA paradigm, if you wanted to parse the data from a video you’d need several AI models running concurrently. You’d need a model that’s been trained on videos…
This story continues at The Next Web
Or just read more coverage about: Google








No comments:
Post a Comment